ChatGPT beaten by 1960s computer program in Turing test study
ELIZA outperforms modern AI in what one researcher describes as ‘embarrassing’ for OpenAI
An early computer program built in the 1960s has beaten the viral AI chatbot ChatGPT at the Turing test, designed to differentiate humans from artificial intelligence.
Researchers from UC San Diego in the US tested the early chatbot ELIZA, created in the mid-1960s by MIT scientist Joseph Weizenbaum, against modern versions of the technology.
They found that ELIZA outperformed OpenAI’s GPT-3.5 AI, which powers the company’s free version of ChatGPT.
The Turing test has been the benchmark for determining a machine’s ability to imitate human conversation ever since it was first conceived in 1950 by British computer scientist Alan Turing.
The latest study required 652 human participants to judge whether they were talking to another human or an AI chatbot over the internet.
OpenAI’s GPT-4 chatbot, which is more powerful than the free version of the technology, was able to trick the study’s participants more frequently than ELIZA, with a success rate of 41 per cent.
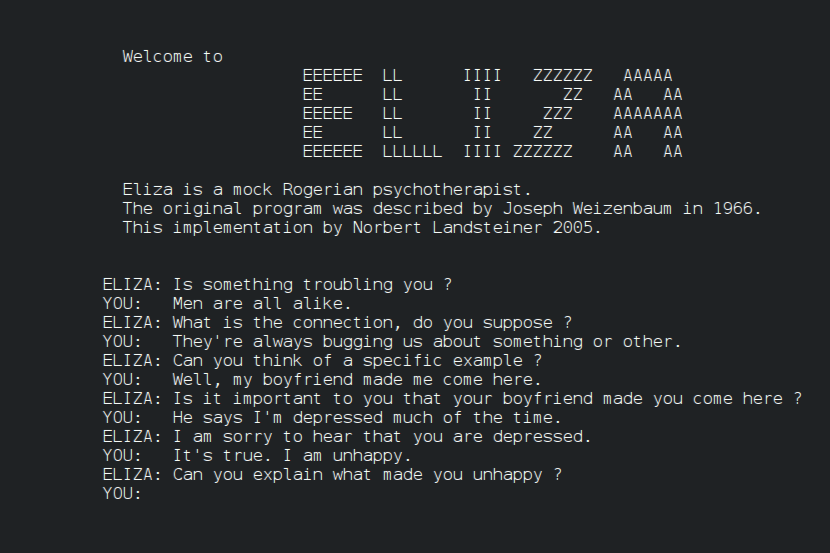
ELIZA was able to pass itself off as a human 27 per cent of the time, while GPT-3.5 had a success rate of just 14 per cent.
AI expert Gary Marcus described the success of ELIZA as “embarrassing” for modern tech companies working on AI chatbots, however other academics argued that ChatGPT was not designed to perform well in the Turing test.
“I think the fact that GPT-3.5 loses to ELIZA is not that surprising when you read the paper,” Ethan Mollick, an AI professor at the Wharton School in the US, posted on X (formerly Twitter).
“OpenAI has considered impersonation risk to be a real concern, and has RLHF [reinforcement learning from human feedback] to ensure ChatGPT doesn’t try to pass as human. ELIZA very much is designed to pass using our psychology.”
One of the reasons noted in the study for participants mistaking ELIZA for a human was that it was “too bad” to be a current AI model, and therefore “was more likely to be a human intentionally being uncooperative”.
Arvind Narayanan, a computer science professor at Princeton who was not involved in the research, said: “As always, testing behaviour doesn’t tell us about capability. ChatGPT is fine-tuned to have a formal tone, not express opinions, etc., which makes it less humanlike.”
The study, titled ‘Does GPT-4 pass the Turing test’, is yet to be peer reviewed.
Join our commenting forum
Join thought-provoking conversations, follow other Independent readers and see their replies
Comments